Geographical Cross Mapping Cardinality
Wenbo Lyu
Last
update: 2026-06-15
Last run: 2026-06-15
Source: Last run: 2026-06-15
vignettes/main5_gcmc.Rmd
main5_gcmc.RmdMethodological Background
To measure causal strengths from spatial cross-sectional data, GCMC (Geographical Cross Mapping Cardinality) employs a three-stage procedure:
Stage one involves reconstructing the shadow manifolds. Given two spatial variables, \(x\) and \(y\), this step requires determining a suitable embedding dimension \(E\) and a spatial lag step \(\tau\). For each spatial unit \(i\), the attribute values from its spatial neighbors at spatial lag orders \(\tau, 2\tau, \dots, E\tau\) are collected. These values are then summarized—commonly using the mean—to construct an embedding vector for each unit. Aggregating these vectors across all spatial units results in the reconstructed shadow manifolds, denoted as \(M_x\) and \(M_y\).
Stage two constructs the intersectional cardinality (IC) curve, which serves to evaluate causal strength. To measure whether \(y\) causally affects \(x\), one computes, for each \(k\), the overlap between the \(k\) nearest neighbors of \(M_y\) and the corresponding “projected” neighbors traced through \(M_x\). Specifically, for each point in \(M_x\), its \(k\) nearest neighbors are identified, and their mapped neighbors in \(M_y\) are compared with the direct neighbors of \(M_y\). The IC curve is formed by recording the number of shared neighbors across a range of \(k = 1, 2, \dots, n\). This process can also be reversed to test for causality from \(x\) to \(y\).
Stage three involves quantifying and validating the causal strengths. The area under the IC curve (AUC) provides a numerical measure of causal strength. To determine whether the observed causal strength is statistically significant, a hypothesis test is performed: the null assumes no causality, while the alternative assumes its presence. The DeLong palcements method is applied to evaluate the difference in AUCs under these hypotheses. It also yields statistical significance and confidence intervals, supporting reliable causal inference.
Usage examples
Example of spatial vector data
Load the spEDM package and its county-level population
density data:
library(spEDM)
popd_nb = spdep::read.gal(system.file("case/popd_nb.gal",package = "spEDM"))
## Warning in spdep::read.gal(system.file("case/popd_nb.gal", package = "spEDM")):
## neighbour object has 4 sub-graphs
popd = readr::read_csv(system.file("case/popd.csv",package = "spEDM"))
## Rows: 2806 Columns: 7
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (7): lon, lat, popd, elev, tem, pre, slope
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
popd_sf = sf::st_as_sf(popd, coords = c("lon","lat"), crs = 4326)
popd_sf
## Simple feature collection with 2806 features and 5 fields
## Geometry type: POINT
## Dimension: XY
## Bounding box: xmin: 74.9055 ymin: 18.2698 xmax: 134.269 ymax: 52.9346
## Geodetic CRS: WGS 84
## # A tibble: 2,806 × 6
## popd elev tem pre slope geometry
## * <dbl> <dbl> <dbl> <dbl> <dbl> <POINT [°]>
## 1 780. 8 17.4 1528. 0.452 (116.912 30.4879)
## 2 395. 48 17.2 1487. 0.842 (116.755 30.5877)
## 3 261. 49 16.0 1456. 3.56 (116.541 30.7548)
## 4 258. 23 17.4 1555. 0.932 (116.241 30.104)
## 5 211. 101 16.3 1494. 3.34 (116.173 30.495)
## 6 386. 10 16.6 1382. 1.65 (116.935 30.9839)
## 7 350. 23 17.5 1569. 0.346 (116.677 30.2412)
## 8 470. 22 17.1 1493. 1.88 (117.066 30.6514)
## 9 1226. 11 17.4 1526. 0.208 (117.171 30.5558)
## 10 137. 598 13.9 1458. 5.92 (116.208 30.8983)
## # ℹ 2,796 more rowsThe false nearest neighbours (FNN) method helps identify the appropriate embedding dimension for reconstructing the state space of a time series or spatial cross-sectional data. A low embedding dimension that minimizes false neighbours is considered optimal.
spEDM::fnn(popd_sf, "popd", E = 1:15, eps = stats::sd(popd_sf$popd))
## [spEDM] Output 'E:i' corresponds to the i-th valid embedding dimension.
## [spEDM] Input E values exceeding max embeddable dimension were truncated.
## [spEDM] Please map output indices to original E inputs before interpretation.
## E:1 E:2 E:3 E:4 E:5 E:6
## 0.9643620813 0.5516749822 0.1813970064 0.0548823949 0.0138987883 0.0035637919
## E:7 E:8 E:9 E:10 E:11 E:12
## 0.0017818959 0.0010691376 0.0035637919 0.0021382751 0.0010691376 0.0010691376
## E:13 E:14
## 0.0014255167 0.0007127584The false nearest neighbours (FNN) ratio decreased to approximately \(0.001\) when the embedding dimension E reached \(11\), and remained relatively stable thereafter. Therefore, we adopted \(E = 11\) as the embedding dimension for subsequent GCMC analysis.
Adopt an empirical k value derived from the square root of the product of embedding dimension and number of prediction samples:
Then, run GCMC:
# temperature and population density
g1 = spEDM::gcmc(popd_sf, "tem", "popd", E = 11, k = 176, nb = popd_nb, progressbar = FALSE)
g1
## neighbors tem->popd popd->tem
## 1 176 0.58668 0.07818957
# elevation and population density
g2 = spEDM::gcmc(popd_sf, "elev", "popd", E = 11, k = 176, nb = popd_nb, progressbar = FALSE)
g2
## neighbors elev->popd popd->elev
## 1 176 0.2730178 0.07644628
# elevation and temperature
g3 = spEDM::gcmc(popd_sf, "elev", "tem", E = 11, k = 176, nb = popd_nb, progressbar = FALSE)
g3
## neighbors elev->tem tem->elev
## 1 176 0.2188468 0.4734956Here we define two functions to process the results and plot the causal strengths matrix.
.process_xmap_result = \(g){
tempdf = g$xmap
tempdf$x = g$varname[1]
tempdf$y = g$varname[2]
tempdf = dplyr::select(tempdf, 1, x, y,
x_xmap_y_mean,x_xmap_y_sig,
y_xmap_x_mean,y_xmap_x_sig,
dplyr::everything())
g1 = tempdf |>
dplyr::select(x,y,y_xmap_x_mean,y_xmap_x_sig)|>
purrr::set_names(c("cause","effect","cs","sig"))
g2 = tempdf |>
dplyr::select(y,x,x_xmap_y_mean,x_xmap_y_sig) |>
purrr::set_names(c("cause","effect","cs","sig"))
return(rbind(g1,g2))
}
plot_cs_matrix = \(.tbf,legend_title = "Causal Strength"){
.tbf = .tbf |>
dplyr::mutate(sig_marker = dplyr::case_when(
sig > 0.05 ~ sprintf("paste(%.4f^'#')", cs),
TRUE ~ sprintf('%.4f', cs)
))
fig = ggplot2::ggplot(data = .tbf,
ggplot2::aes(x = effect, y = cause)) +
ggplot2::geom_tile(color = "black", ggplot2::aes(fill = cs)) +
ggplot2::geom_abline(slope = 1, intercept = 0,
color = "black", linewidth = 0.25) +
ggplot2::geom_text(ggplot2::aes(label = sig_marker), parse = TRUE,
color = "black", family = "serif") +
ggplot2::labs(x = "Effect", y = "Cause", fill = legend_title) +
ggplot2::scale_x_discrete(expand = c(0, 0)) +
ggplot2::scale_y_discrete(expand = c(0, 0)) +
ggplot2::scale_fill_gradient(low = "#9bbbb8", high = "#256c68") +
ggplot2::coord_equal() +
ggplot2::theme_void() +
ggplot2::theme(
axis.text.x = ggplot2::element_text(angle = 0, family = "serif"),
axis.text.y = ggplot2::element_text(color = "black", family = "serif"),
axis.title.y = ggplot2::element_text(angle = 90, family = "serif"),
axis.title.x = ggplot2::element_text(color = "black", family = "serif",
margin = ggplot2::margin(t = 5.5, unit = "pt")),
legend.text = ggplot2::element_text(family = "serif"),
legend.title = ggplot2::element_text(family = "serif"),
legend.background = ggplot2::element_rect(fill = NA, color = NA),
legend.direction = "horizontal",
legend.position = "bottom",
legend.margin = ggplot2::margin(t = 1, r = 0, b = 0, l = 0, unit = "pt"),
legend.key.width = ggplot2::unit(20, "pt"),
panel.grid = ggplot2::element_blank(),
panel.border = ggplot2::element_rect(color = "black", fill = NA)
)
return(fig)
}Organize the results into a long table:
res1 = list(g1,g2,g3) |>
purrr::map(.process_xmap_result) |>
purrr::list_rbind()
res1
## cause effect cs sig
## 1 tem popd 0.58668001 1.102583e-02
## 2 popd tem 0.07818957 2.817486e-119
## 3 elev popd 0.27301782 3.996458e-13
## 4 popd elev 0.07644628 1.466165e-125
## 5 elev tem 0.21884685 6.996949e-22
## 6 tem elev 0.47349561 4.541299e-01Visualize the result:
plot_cs_matrix(res1)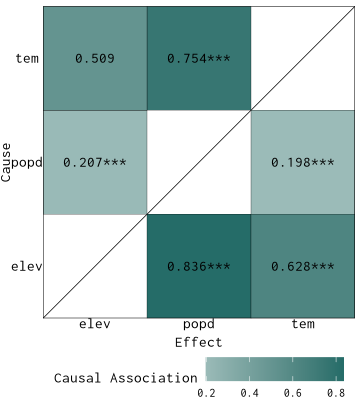
Example of spatial raster data
Load the spEDM package and its farmland NPP data:
library(spEDM)
npp = terra::rast(system.file("case/npp.tif", package = "spEDM"))
# To save the computation time, we will aggregate the data by 4 times
npp = terra::aggregate(npp, fact = 4, na.rm = TRUE)
npp
## class : SpatRaster
## size : 101, 121, 5 (nrow, ncol, nlyr)
## resolution : 40000, 40000 (x, y)
## extent : -2625763, 2214237, 1877078, 5917078 (xmin, xmax, ymin, ymax)
## coord. ref. : CGCS2000_Albers
## source(s) : memory
## names : npp, pre, tem, elev, hfp
## min values : 200.50, 391.9702, -47.8194, -68.03307, 0.08262913
## max values : 15299.53, 23675.4185, 262.3801, 5193.36182, 41.80874634
# Inspect NA values
terra::global(npp,"isNA")
## isNA
## npp 8109
## pre 8075
## tem 8075
## elev 8070
## hfp 8205
terra::ncell(npp)
## [1] 12221
nnamat = terra::as.matrix(npp[[1]], wide = TRUE)
nnaindice = which(!is.na(nnamat), arr.ind = TRUE)
dim(nnaindice)
## [1] 4112 2Determining optimal embedding dimension:
spEDM::fnn(npp, "npp", E = 1:25,
eps = stats::sd(terra::values(npp[["npp"]]),na.rm = TRUE))
## [spEDM] Output 'E:i' corresponds to the i-th valid embedding dimension.
## [spEDM] Input E values exceeding max embeddable dimension were truncated.
## [spEDM] Please map output indices to original E inputs before interpretation.
## E:1 E:2 E:3 E:4 E:5 E:6
## 0.9714842798 0.4732490272 0.0926556420 0.0043774319 0.0000000000 0.0000000000
## E:7 E:8 E:9 E:10 E:11 E:12
## 0.0000000000 0.0004863813 0.0000000000 0.0000000000 0.0002431907 0.0000000000
## E:13 E:14 E:15 E:16 E:17 E:18
## 0.0007295720 0.0009727626 0.0000000000 0.0004863813 0.0000000000 0.0000000000
## E:19 E:20 E:21 E:22 E:23 E:24
## 0.0000000000 0.0000000000 0.0000000000 0.0000000000 0.0000000000 0.0000000000At \(E = 5\), the false nearest neighbor ratio stabilizes at \(0\) and remains constant thereafter. Therefore, \(E = 5\) is selected for the subsequent GCMC analysis.
Adopt an empirical k value derived from the square root of the product of embedding dimension and number of prediction samples:
# precipitation and npp
g1 = spEDM::gcmc(npp, "pre", "npp", E = 5, k = 144, progressbar = FALSE)
g1
## neighbors pre->npp npp->pre
## 1 144 0.5995853 0.557581
# temperature and npp
g2 = spEDM::gcmc(npp, "tem", "npp", E = 5, k = 144, progressbar = FALSE)
g2
## neighbors tem->npp npp->tem
## 1 144 0.7325424 0.7235725
# precipitation and temperature
g3 = spEDM::gcmc(npp, "pre", "tem", E = 5, k = 144, progressbar = FALSE)
g3
## neighbors pre->tem tem->pre
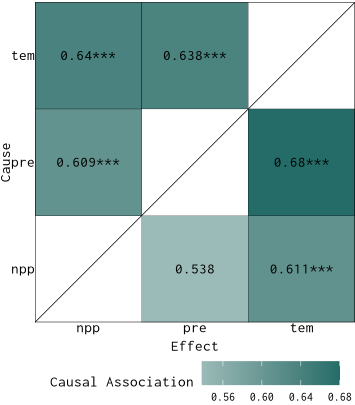
## 1 144 0.6616995 0.6358989Organize the results into a long table:
res2 = list(g1,g2,g3) |>
purrr::map(.process_xmap_result) |>
purrr::list_rbind()
res2
## cause effect cs sig
## 1 pre npp 0.5995853 9.477523e-03
## 2 npp pre 0.5575810 1.389267e-01
## 3 tem npp 0.7325424 2.978542e-11
## 4 npp tem 0.7235725 2.734370e-10
## 5 pre tem 0.6616995 1.485632e-05
## 6 tem pre 0.6358989 3.248357e-04Visualize the result:
plot_cs_matrix(res2)